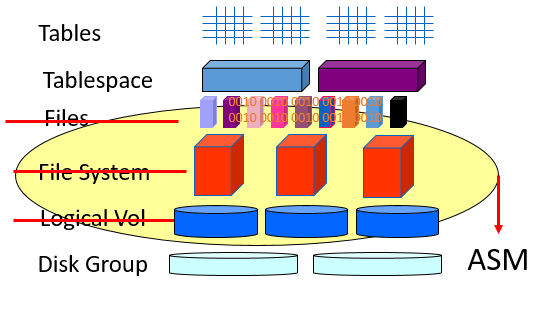
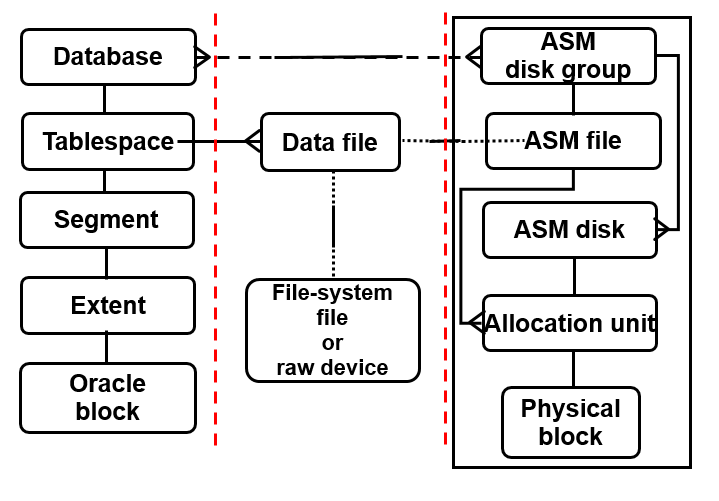
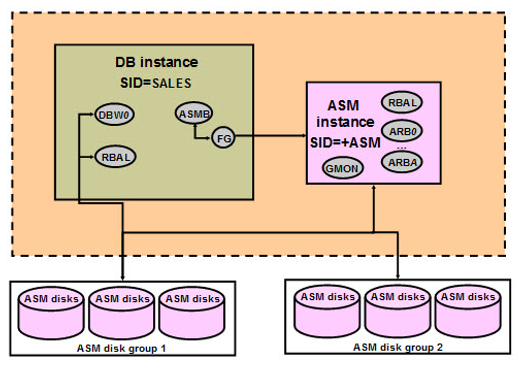
ASM 在管理上可以使用 SQL*Plus 、 ASMCA ,與 ASMCMD 。透過 SQL*Plus 可以直接進入 ASM Instance 進行管理,指定 ORACLE_SID 為 +ASM1 (RAC 第一個 node 的 ASM Instance) 並以 sysasm 權限進入:
進入後就與一般的 Database Instance 操作無異,可以進行查詢、修改參數…等,對於 ASM Instance 來說,最高權限為 sysasm 而非 sysdba ,使用 sysdba 進入後有些操作會無法進行,例如 create diskgroup 就無法使用 sysdba 進行操作。 ASM Instance 當中比較會異動到的參數為 asm_diskstring 與 asm_power_limit , asm_diskstring 是用來設定讀取 ASM Disk 的路徑,目的是要讓 ASM Instance 知道 ASM Disk 所在的位置,例如 ASM Disk Group 是由 /dev/sda 、 /dev/sdb …等 Disk 所組成,那麼 asm_diskstring 就會設定為 /dev/sd* ; asm_power_limit 是用來設定 ASM Disk Rebalance 的速度,預設為 1 表示最慢,最大可設置為 11 ,如果 ASM Disk Group 的 COMPATIBLE.ASM 屬性設置為 11.2.0.2 以上,則 asm_power_limit 最大可為 1024 ,當有 ASM Disk 新增或移除時, ASM Disk Group 便會進行 Rebalance 的動作,希望它 Rebalance 越快完成, asm_power_limit 就可以設置大一點,然而 Rebalance 越快也代表者需要消耗較多的 I/O 資源在 Rebalance 作業上,對效能具有一定的影響。
進入到 ASM Instance 除了參數的設定外,最常做的就是檢查 ASM Disk Group 與 ASM Disk 的狀態,這些可以透過 v$asm_diskgroup 、 v$asm_disk 與 v$asm_attribute 來進行查詢,例如檢查 ASM Disk Group 的狀態、可用空間…等,就可以使用 v$asm_diskgroup 來查詢:

如果要知道目前 Disk Group 有哪些 ASM Disk 以及是否有可用的 ASM Disk ,則是透過 v$asm_disk 來查詢:

v$asm_attribute 則是用來查詢每個 Disk Group 的屬性,其中比較重要的屬性是 compatible.asm 、 compatible.rdbms 與 disk_repair_time :

compatible.asm 用來設置能夠使用此 Disk Group 的 ASM Instance 最低版本,例如 compatible.asm 設置為 10.1 ,那麼就表示 Oracle 10g 以上版本的 ASM Instance 都可以使用此 Disk Group ,如果 compatible.asm 設置為 11.2 ,那麼由 Oracle 10g 所啟動的 ASM Instance 就無法存取此 Disk Group ,必須要 Oracle 11g 以上版本的 ASM Instance 才可以存取; compatible.rdbms 表示能夠使用此 Disk Group 的資料庫最低版本,例如 compatible.rdbms 設置為 11.2.0 ,那麼只有在 Oracle 11R2 以後版本的資料庫才可以把 Data File 放置在此 Disk Group 當中; disk_repair_time 表示 Disk Group 可容許 ASM Disk 遺失的時間,例如有實體的硬碟損壞,那麼在 Disk Group 當中便會看到此 ASM Disk 狀態為 OFFLINE , ASM 會暫時保留這個 ASM Disk 在 Disk Group 裡面,如果超過了 disk_repari_time 的設定時間還沒有修復好這個損壞的 Disk ,那麼 ASM Disk Group 才會把這個遺失的 Disk 正式移出 Disk Group 。要修改 Disk Group 屬性可以透過 alter diskgroup set attribute 指令修改,例如將 disk_repair_time 修改為 24h :
這邊要注意的是,不是每個 attribute 都可以隨意更改,像是 compatible 屬性只能往上調整不能往下調整,例如 compatible.rdbms 已經設置為 11.2.0 就不能修改為 10.1 ,假設此時還有 Oracle 10g 的資料庫存在,那麼就會變得無法使用,因此修改此參數必須謹慎;有些 attribute 是在 Disk Group 建立後就無法更改,例如 au_size ,如果嘗試修改的話便會報錯:

ASMCA 是一個圖形化介面的工具,可以用來新增刪除 Disk Group 、幫 Disk Group 添加或移除 ASM Disk ,以及建立 ACFS 。設定好 XWindow 工具之後執行 asmca 便可以使用,例如新增一個 Disk Group 只需點選 create 以及選擇要加入的 ASM Disk 即可:

透過 asmca 來建立一個 ACFS 也是相當的方便,首先由一個 Disk Group 建立出一個 Volume :
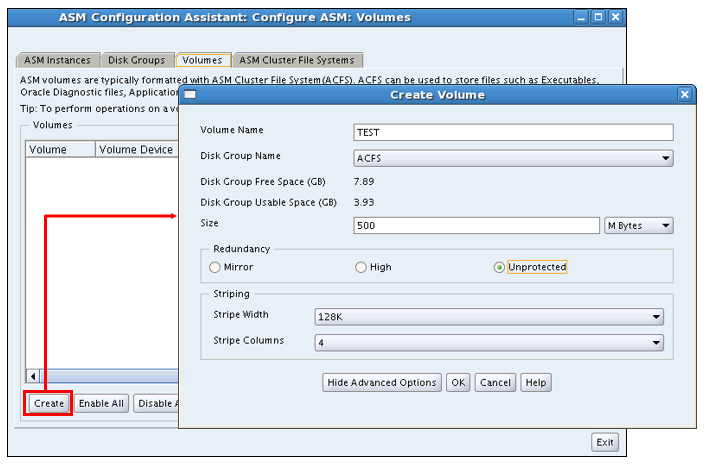
再由此 Volume 建立出 ACFS 即可:

不同版本下的 asmca 介面略有不同,但整體的操作方式是一樣的。
ASMCMD 是一個 command line tool ,由於 ASM Disk Group 不會顯示在作業系統上面,無法使用作業系統的命令來檢視 Disk Group 的內容與狀態,而 ASMCMD 就是用來檢視 ASM Disk Group 所用,首先須設定好 ORACLE_HOME 為 Grid Infrastructure 的安裝目錄, ORACLE_SID 為 +ASM1 ,然後直接執行 asmcmd 就會進入 ASMCMD> 的介面底下,在 ASMCMD> 底下就可以使用作業系統般的指令來檢視 Disk Group 的內容,例如 ls 、 cd …等指令都可在 ASMCMD> 底下執行:

早期 ASM 剛推出的時候,由於在作業系統上不可見,常常被詬病為黑盒子,但有了 asmcmd 這項工具後,檢視 Disk Group 的內容便可以一目了然,在管理上添加了許多便利性。
進入到 asmcmd 以後,可以簡單的執行 lsdg ,這個命令會列出所有 Disk Group 的狀態與可用空間,其實內容就與查詢 v$asm_diskgroup 的內容一樣,只不過透過 asmcmd 查詢更加方便:
其中 Total_MB 表示整個 Disk Group 的總空間; Free_MB 表示整個 Disk Group 剩餘的可用空間,這裡不計算冗餘; Req_mir_free_MB 表示當有 Disk 損壞時,剩下的 Disk 需要保留多少空間才可以維持冗餘的水準; Usable_file_MB 表示在計算有 Disk 損壞的情況下,還能夠維持冗餘水準的可用空間。例如一個 Normal Redundancy 的 Disk Group DATADG ,裡面總共設定三個 Failure Group (FG1,FG2,FG3) ,每個 Failure Group 都有兩顆 Disk ,每個 Disk 100G :
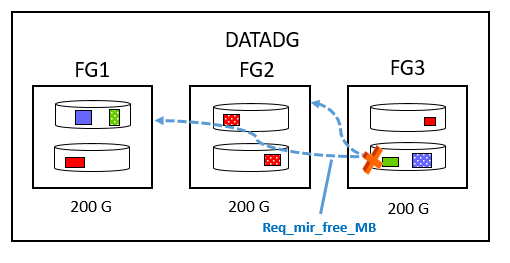
以上 Total_MB 為 600G ;假設已經使用了 50G ,那麼此時的 Free_MB 就為 550G ; Req_mir_free_MB 會從寬計算,會以最大的 Failure Group 大小作為計算值,因此這邊的 Req_mir_free_MB = 200G ,也就是說當有 Disk 損壞時,剩下的可用空間必須要大於 200G 才能夠保持兩份的 Normal Redundancy 冗餘; Usable_file_MB 表示安全可用空間,也就是說在計算當有 Disk 損壞時還能夠保持兩份冗餘的情況下的可用空間,因此這邊的 Usable_file_MB = (Free_MB - Req_mir_free_MB) / 2 (Normal Redundancy 可用空間要除以 2) = (550 – 200)/2 = 175G 。
由於 Usable_file_MB 是在預先考量有 Disk 損壞的情況下所計算出來的,因此當 Free_MB 小於 Req_mir_free_MB 的時候, Usable_file_MB 就會出現負值,此時並不代表空間不足夠,只是說當有 Disk 損壞時無法維持冗餘的水準,如果 Disk Group 的空間足夠的話,建議平時還是維持安全可用空間的水準 (Usable_file_MB > 0) 。
由於 ASM 的架構不同於一般的檔案系統,因此剛推出的時候會讓人覺得陌生,不過經由這些工具的輔助,相信 DBA 也會對這項功能越來越熟悉,管理起來會更得心應手。