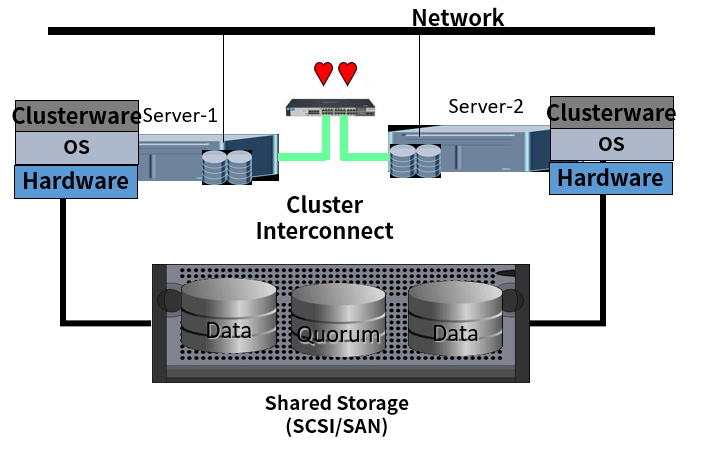
Cache Fusion 是 Oracle RAC 特有的機制,意思是 SGA 裡面的 Data Block 可以透過 Internal Connect 在 RAC 的節點之間互相傳輸,藉此減少對 Disk I/O 的頻率,一句查詢的 SQL Statement 在 Single Instance Database 執行與在 RAC Database 執行所經歷的流程略有不同:

select 的語法在 Single Instance Database 執行時,會先到 Buffer Cache 裡面查找是否有需要的資料,如果有,則從 Buffer Cache 獲取資料並回傳結果;如果沒有,則將資料重新從 Disk 讀取出來。如果這句語法是在 RAC Database 執行時,首先一樣會從這個節點的 Buffer Cache 查找是否有需要的資料,與 Single Instance Database 不同的是,當本地節點的 Buffer Cache 沒有需要的資料時, RAC Database 會嘗試的查找其它節點的 Buffer Cache 是否有存放這些資料,如果其它節點有,那麼就將這些資料從其它節點的 Buffer Cache 傳送過來使用,這個動作就叫做 Cache Fusion ,如果所有節點的 Buffer Cache 都沒有這些資料,那麼才會從 Disk 重新將資料讀取出來。
那麼 RAC 節點之間怎麼知道互相的 Cache 裡面有沒有需要的資料 !? 靠的就是 Global Cache Service (GCS) 、 Global Enqueue Service (GES) 以及 Global Resource Directory (GRD) 這三個機制。
Global Cache Service 會於作業系統上產生 LMSn 這個 Process , n 代表數字,表示 LMS 可以有多個 Process (lms0 、 lms1 、 lms2 …) , LMS 的數量由參數 GC_SERVER_PROCESSES 所決定,預設會依據系統 CPU 的數量來調整 GC_SERVER_PROCESSES 。 Global Cache Service 主要的用途是用來紀錄與追蹤 Data Block 的位置以及它所處的狀態。
Global Enqueue Service 會於作業系統上產生 LMD 這個 Process ,用來管理與處理 Global Cache 中與 lock 相關的事務。
Global Resource Directory 主要是用來存放 Global Resource 的資訊,例如 Data Block 的位置、狀態、模式與角色以及 master 的所在地 … 等,這些訊息是經由 Global Cache Service 來更新。 Global Resource Directory 存放在 SGA 裡面,每個節點自己都有一份 Global Resource Directory ,最終由 Global Cache Service 來統合與管理。
在了解了這些 Global Service 之後,接下來就來看看 Cache Fusion 是如何運行的,在進行 Cache Fusion 之前,首先來了解 Global Resource 有哪些角色與狀態。
角色方面分為 Local 與 Global 兩種, Local 表示這個 Data Block 是從這個節點第一次由 Disk 所讀取出來,其它節點都沒有這個 Block Copy 或 Dirty Copy ,當其它節點需要讀取這個 Block 並請求傳輸時,這個時候這個 Block 的角色就會由 Local 轉變為 Global 並且進行傳輸,當 Data Block 轉變為 Global 之後就無法降級為 Local ,因為它已經是在外流動了,所以最終寫入 Disk 的 Dirty Cache 它的角色一定是 Global ,當 Dirty Cache 被寫入後再重新由 Disk 讀取出來,它才會為 Local 。
Global Resource 的模式可以分為三種, NULL (N) 、 Shared (S) 與 Exclusive (X) 。 Null (N) 為普通模式,表示沒有對這個 Block 做任何的請求; Shared (S) 為讀取模式,有讀取 Block 需求的時候必需切換為 Shared Mode ; Exclusive (X) 為排它模式,有修改 Block 需求的時候必需切換為 Exclusive Mode 。
每個 Data Block 都有屬於自己的 Resource Master ,這個 Resource Master 不一定存放在同一個節點當中,例如 Data Block 1 它的 Master 可能在節點 A , Data Block 2 它的 Master 可能在節點 B ,而這些資訊都是存放在 Global Resource Directory 當中,在進行 Cache Fusion 之前,所被請求的 Data Block 都必須去詢問 Master ,然後再由 Master 來發號施令派送,整個流程的核心要角,就是經由 Global Cache Service 來達成。
例如現在有四個節點的 RAC , Instance A ~ D ,目前資料為 1008 的 Data Block 的 Resource Master 在節點 D :

接下來總共有四個情境來進行 Cache Fusion :
Read with No Transfer :

1. 首先 C 節點需要讀取 1008 這筆資料, C 節點此時必須向 Global Cache Service 發出讀取資料的請求, Global Cache Service 接收到請求之後,便會找出擁有 1008 這個 Data Block 的 Resource Master ,在此為節點 D ,並告知 Resource Master 節點 C 有讀取資料的請求。
2. Resource Master (節點 D) 收到這個請求之後,便會把這個 Resource 的模式由 Null 改為 Shared (N 🡪 S) 並且把 Resource 角色設定為 Local ,然後紀錄在 Global Resource Directory ,最後將這個訊息發送給節點 C ,告知它已經可以取得這個 Resource 的 S Mode 。
3. 節點 C 取得這個 Resource 的 S Mode 之後,由於是第一次讀取,所以開始從 Disk 讀取出具有 1008 這筆資料的 Data Block 。
4. Disk 將具有 1008 這筆資料的 Data Block Image 發送到節點 C , C 節點得到這筆資料後,自此完成整個讀取的步驟。
Read to Write Transfer :

1. 此時節點 B 需要把 1008 這筆資料修改為 1009 ,因此先透過 Global Cache Service 向 Resource Master (節點 D) 發出更改資料的請求。
2. Resource Master (節點 D) 接收到這個請求之後,知道 1008 這個 Data Block 目前為節點 C 擁有,因此發送訊息給節點 C ,告知它節點 B 需要更改這筆資料,請它把這個 Data Block 送過去給節點 B 。
3. 節點 C 接收到傳送 Block 的請求之後,必須先把這個 Data Block 的模式由 Shared 改為 Null (S 🡪 N) ,然後把 Null Mode 的這個 Data Block 發送給節點 B 。
4. 節點 B 接收到節點 C 發送過來的 Data Block 之後,由於是做資料的更改,因此必須把這個 Data Block 的模式由 Null 改為 Exclusive (N 🡪 X) ,然後再把 1008 這筆資料修改為 1009 。
Write to Write Transfer :

1. 這時節點 A 需要把這筆資料修改為 1013 ,同樣的對 Resource Master (節點 D) 發出修改資料的請求。
2. Resource Master (節點 D) 收到節點 A 的請求之後,知道這個 Data Block 最終為節點 B 擁有,因此告知節點 B 請它把這個 Data Block Image 傳送到節點 A 。
3. 節點 B 收到 Resource Master (節點 D) 的請求之後,必須先把這個 Data Block 的模式由 Exclusive 改為 Null (X 🡪 N) 才可以將它傳送,由於節點 B 是做了資料的變更,這個時候必須做 log flush 的動作,也就是把這筆異動的交易資訊確實的寫入 Transaction Log ,在完成 log flush 之後才能釋放 X 並修改為 N ,然後再把此 Data Block Image 送給節點 A 。
4. 節點 A 收到這個 Data Block 之後,就可以把它的模式由 Null 改為 Exclusive (N 🡪 X) ,然後將資料修改為 1013 。
Write to Read Transfer :

1. 最終由節點 C 再度發出讀取這個 Data Block 的請求。
2. Resource Master (節點 D) 接收到這個請求之後,請最後的 Block 擁有者節點 A 將這個 Data Block Image 發送給節點 C 。
3. 節點 A 接收到這個請求之後,由於是讀取的請求,所以不用等到 log flush 之後才能傳送 Data Block Image ,此時直接把 Data Block 的模式由 Exclusive 改為 Shared (X 🡪 S) 然後將這個 Data Block 發送給節點 C 。
4. 節點 C 接收到這個 Data Block 之後,這個 Data Block 有可能是 log flush 之前的 Block ,或者是已經完成 log flush 的 Block ,這邊節點 C 並不能確定,於是節點 C 會去記錄讀取這個 Data Block 當下的 SCN ,並且把這個訊息反饋回 Resource Master (節點 D) ,表示這個 Block 的最終狀態是處於這個 SCN 下的這個資料,這個用意是為了避免節點 A 發送 Block 時還沒有做 log flush ,萬一交易資料遺失的時候 (Instance Crash) ,至少在 Recovery 的過程當中, Resource Master 會知道在這個 SCN 之下的這個 Data Block 是什麼狀態以及它的資料是什麼,避免資料錯誤。
由上述 Cache Fusion 的情境可以知道,每當要做一個動作的時候都必須先去向這個 Resource 的 Master 提出請求,那麼要如何知道某個 Resource 的 Master 是位於哪一個節點 ? 透過查詢 v$gcspfmaster_info 就可以得知:

如果 previous_master 顯示為 32767 表示之前沒有做過 Re-Master 的動作,從 Oracle 11g 開始引進了 DRM (Dynamic Resource Management) 機制,用意是將最常存取這個 Data Block 的節點設定為這個 Resource 的 Master ,減少 Cache Fusion 過程中不斷詢問 Master 的成本。
雖然 Oracle RAC 的 Cache Fusion 機制可以有效的減少 Disk I/O ,但這也是一個雙面刃,由上述情境可以知道, Cache Fusion 需要不斷的詢問 Master 、改變 Resource 的模式 (N 、 S 、 X) 以及傳送 Data Block Image ,過程中可能會發生效能上的問題,引發 gc 相關的等待事件。如果想要避免 gc 的等待事件,最好方法就是減少 Cache Fusion 的發生,將不同 Application 的作業進行節點上的分流,以此減少跨節點的 Block 請求,進而減少 gc 事件的發生。