我們在撰寫 SQL 的時候應該注意一些小細節,避免使用這些低效率的語法。
Rule-Based 下需注意 Table 放置的順序
Oracle 優化器在 Rule-Based 底下,訪問 Table 的順序從 From 子句由右至左開始訪問,放置在 From 子句最右邊的 Table 將被視為驅動表,因此將資料最少的 Table 放置在最右邊會使整個 SQL 的效能較有效率。已知employees 有 107 rows , departments 有 28 rows ,比較兩句 SQL 如下 :
由於 departments 的資料量比 employees 還來得少,因此 SQL 1 會比SQL 2 還來的有效率 :
SQL 1 耗時 0.02s :

SQL 2 耗時 0.06s :

select 語法應避免使用 "*"
若使用 "select * from" 的語法, SQL 在解析的過程當中,仍然會將 "*" 轉換為欄位名稱,而這個工作對資料庫來說也是從 Data Directory 查詢而來的,使得 SQL 在 Parse 的過程中將使用更多的時間,因此我們在撰寫 SQL的時候應盡量避免使用 "select * from" 的方式。
減少對資料庫訪問的次數
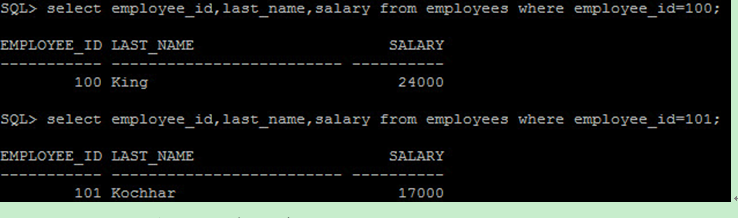
SQL 生命週期的最後階段將從資料庫 fetch 資料,我們可以透過設定 array size 來減少對資料庫訪問的次數,除此之外,也可以透過調整 SQL 語法來減少對資料庫的訪問,例如查詢 employee_id=100 與 employee_id=101 的資料,一般都會以兩句 SQL 表示:
時執行兩次 SQL 語法,因此將訪問資料庫兩次 :
若能夠將兩句 SQL 合併,那麼就只需訪問資料庫一次,減少 fetch 時間 :

不過要注意的是,我們不要陷入 SQL 合併的迷思,如果合併起來變成一段很冗長且複雜的 SQL ,那麼有可能導致 SQL Execution 的時間加長,縱使減少了 Fetch 時間也彌補不了 Execution 的耗時,必須先以優化 Execution 時間為優先,其次才是優化 Fetch 時間。
避免使用Having語法
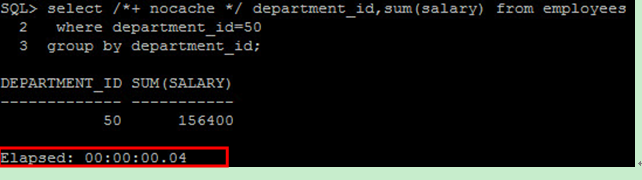
在 SQL 語句含有 group by 語法時,應使用 where 來替代 Having , Having 語句是將 group by 完後所有的資料再進行條件的過濾,而 where 語句則是先過濾完資料再進行 group by 的動作,所需 group by 的資料較少,效能也就越好。例如計算部門 id 為 50 的總薪資 :
使用having語法需耗時0.1s:

改用 where 條件執行只需耗費 0.04s :
減少查詢的次數
若 SQL 語句中含有子查詢的語法,應盡量減少對 Table 查詢的速度以提高效能,例如一段 update 語法如下 :
此 update 兩個欄位使用了兩次子查詢,耗時 1.45s :

修改 SQL 將兩段子查詢合併之後,減少了對 Table 查詢的次數,效能就有所提升 :

IN 與 EXISTS比較
當一段 SQL 使用到子查詢時,使用 in 或是 exists 語法對於效能有著不同的影響,而 in 與 exists 在行為上也有所不同,例如一段使用 in 的 SQL 如下 :
此 SQL 語法可以轉述如下 :
由此可知若使用 in 語法,此 SQL 將對 t2 這個 Table 進行全表掃描以及排序的動作,因此 t2 的資料量越大,也就是子查詢中的 Table 越大,使用 in 的效能也就越差。
另外一段使用 exists 的 SQL 如下 :
此 SQL 的行為可以轉述如下 :
由此可知當使用 exists 的語法,會對 t1 這個 Table 做全表掃描,然後再將結果與子查詢的結果一一做 mapping ,因此當 t1 的資料量越大,也就是主查詢中的 Table 越大, exists 的效能將會越差。
總結來說,當 SQL 主查詢的資料量小,或是子查詢的資料量越大,較適合使用 exists 語法;反之若 SQL 主查詢的資料量大,或是子查詢的資料量越小,較適合使用 in 語法。例如 :
Table bobj 為大 table ,資料筆數為 157744 rows 。
Table sobj 為小 table ,資料筆數為 100 rows 。
假使主查詢使用大 table(bobj) 子查詢使用小 table(sobj) ,此時使用 in語法優於 exists :
使用 in 語法耗時 0.06s :

而使用 exists 語法需 0.13s :

反之若主查詢使用小 table(sobj) 而子查詢使用大 table(bobj) ,此時使用 exists 語法優於 in :
使用 in 語法耗時 0.04s :

使用 exists 只需 0.01s :

使用 NOT EXISTS 替代 NOT IN
當 Table 的資料不存在 Null 值時, NOT EXISTS 與 NOT IN 語法並無差異,若 Table 資料具有 Null 值時,使用 NOT IN 語法將造成錯誤的結果,為避免查詢的結果錯誤,應使用 NOT EXISTS 替代 NOT IN 。例如 employees 的 department_id 欄位具有 Null 值 :

當子查詢的結果具有 Null 值時, NOT IN 將無法回傳正確結果,例如 :
由於 employees 的 department_id 具有 NULL 值,因此這個查詢無法回傳任何結果 :

使用 NOT EXISTS 替代 NOT IN ,將回傳 16 rows :

同樣的若主查詢的結果具有 NULL 值,使用 NOT IN 將無法計算到為 NULL 的 rows ,例如 :
計算結果為 88 rows :

改用 NOT EXISTS 則會有 89 rows :

所以當子查詢的 Table 具有 NULL 值, NOT IN 無法回傳任何資料;當主查詢的 Table 具有 NULL 值, NOT IN 無法統計為 NULL 的 row ,因此為了避免查詢結果出現誤謬,應盡量以 NOT EXISTS 替代 NOT IN 才是。
使用 JOIN 替代 EXISTS
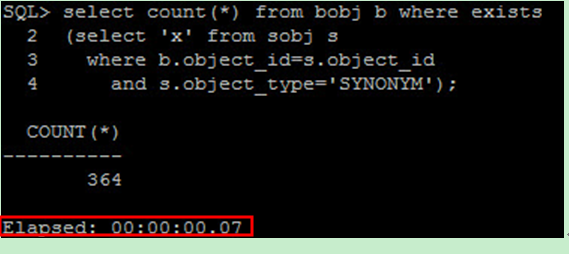
通常來說,直接使用 JOIN 語法會比使用 EXISTS 來得有效率,如果邏輯上能使用 JOIN 解決,就應該避免使用 EXISTS ,例如 :
此時執行時間約 0.07s :
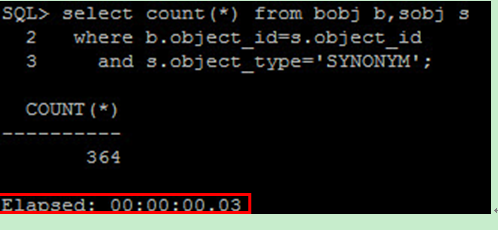
若改用只有 where 條件簡化 SQL ,則只需 0.03s :
使用 >=(<=)替代 > (<)
若 where 條件使用到不等式,例如大於 (>) 小於 (<) ,應以大於等於 (>=) 或小於等於 (<=) 替代之,例如 :
此時應將 SQL 替換如下較為效率 :
這兩段 SQL 所回傳的第一筆資料均為 employee_id=101 的資料列,但第一個查詢需先將資料定位在 employee_id=100 ,然後再往後搜尋從 employee_id=101 開始的資料列,而第二個查詢則是直接定位到 employee_id=101 的這筆資料,因此使用大於等於將來得有效率。
使用 UNION 替代 OR
若 SQL 在 Index 的欄位上使用 OR 條件式,則優化器可能選擇使用 Full Table Scan 而非 Index ,此時應使用 UNION 條件式取代 OR 確保 Index 被使用到,例如 employees 這個 Table 於 department_id 上有 Index(EMP_DEPARTMENT_IX) ,於 manager_id 上有 Index(EMP_MANAGER_IX) ,一段 SQL 如下 :
在 or 的條件下,使用了 Full Table Scan :
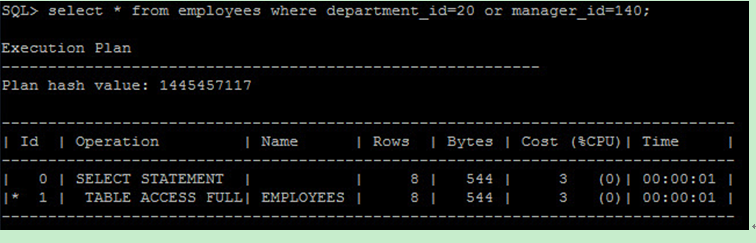
改用 UNION 條件式替換後,此查詢便可使用到 Index :

若資料不重複,使用 UNION ALL 替代 UNION
UNION ALL 與 UNION 差別在於 UNION 會將重複的資料合併且進行排序,若查詢的資料不重複,則使用 UNION ALL 的效能遠優於 UNION 。





