10053 事件可以幫助我們了解 CBO 優化器是如何選擇出 SQL 當前最佳的執行計畫, 10053 事件總共有兩個層級可以設定, Level 2 可以蒐集出欄位的統計資訊 、 SQL 的 access path , join 方式的選擇以及相對應的 cost ; Level 1 可以蒐集出 Level 2 所有的資訊再加上優化器使用的參數設定,以及 Index 的統計資訊。
使用 10053 事件的前提是 SQL 語法必須進行 Hard Parsing ,因為只有經過 Hard Parsing 才能捕捉到優化器是如何運算出 Cost ,否則 10053 事件蒐集出來是沒有任何內容的。 10053 有如下的方式可以進行蒐集 :
使用 explain plan
針對要蒐集 10053 的 SQL 語法使用 explain plan 進行 Hard Parsing 來蒐集 :
使用 oradebug 進行蒐集
利用 oradebug 語法來蒐集 10053 事件 :
使用 DBMS_SQLDIAG 進行蒐集
利用 dbms_sqldiag 可以蒐集特定 SQL_ID 的 10053 事件,例如蒐集 SQL_ID 為 847df3vkcbsvh 的 10053 :
在一個完整的 10053 trace 文件中,會有以下幾個部分 :
原始的 SQL 語法 :

優化器所使用的參數 :

表格相關的各項統計資訊 :

執行計畫的產生過程 :
從這個階段的資訊我們可以看到各項 access path 以及 join 方式所計算出來的 cost ,並且選擇最低的 cost 作為最終的執行計畫 :

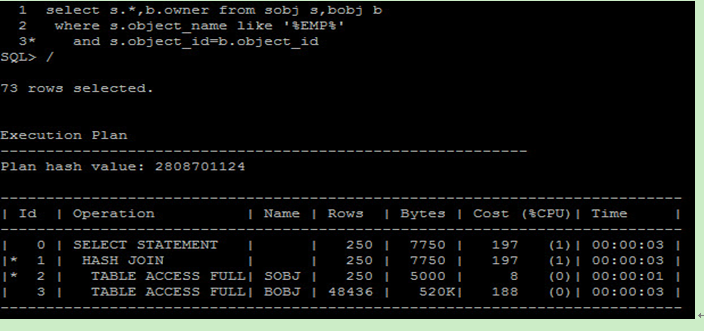
經由 10053 的幫助,我們可以了解為何優化器會選擇這個 Plan ,並且從中可以找出問題所在,我們以下列這個查詢來說,優化器選擇的是 Hash Join :

針對這句 SQL 來蒐集 10053 事件 :

10053 trace 首先揭露了 T1 、 T2 這兩個表格以及系統的統計資訊 :

接下來是 Table 存取路徑的選擇 :

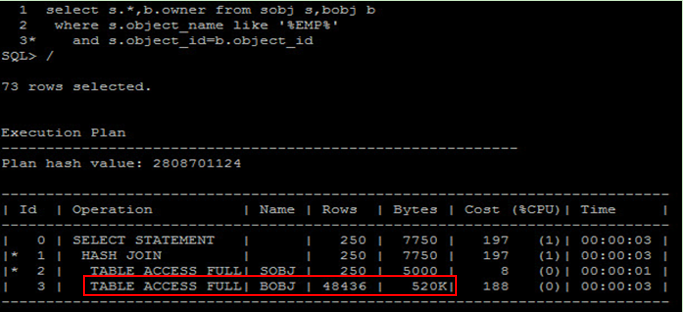
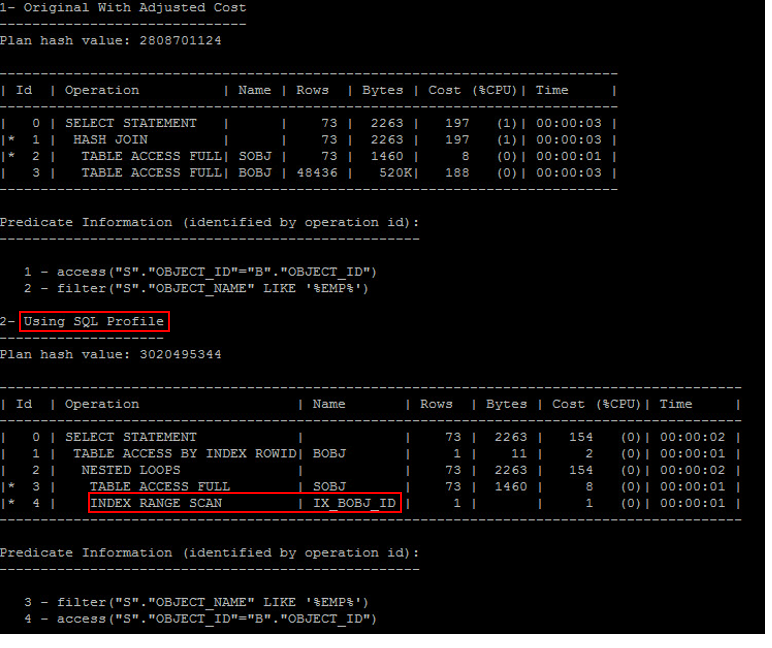
由上述資訊可以得知,使用 Table Scan 的 Cost 為 380.17 ,使用 Index 的 Cost 為 1502.56 ,所以最後會選擇使用 Table Scan 。
最後一個區塊是 Join 方式的選擇 :

由這個區塊我們可以截取到,使用 Nest Loop 的 Cost 為 4207826.48 、使用 Sort Merge Join 的 Cost 為 1303.69 ,使用 Hash Join 的 Cost 為 936.34 ,綜合上述分析, 10053 最後就可以得到結論,這句 SQL 所選用的執行計畫為使用 Hash Join 並且做 Table Scan :

最後我們再利用 10053 來分析一句 SQL 如下 :
雖然 emp 與 dep 這兩個 Table 都有 Index ,但優化器最終選擇的仍然是 Full Table Scan :

透過 10053 trace 可以發現,針對 EMP 這個 Table 使用 Table Scan 的 Cost 為 3 ,而使用 Index 的 Cost 高達 18700.40 :

由這個現象我們懷疑,是否這個 Index 所掃描的 Block 過多導致 Cost 增加太多,有可能是因為 Index 破碎導致 Block 數量過多。
檢視另一個 Table DEP , DEP 總共有 27 筆資料,但 10053 顯示使用 IX_DEP 這個 Index 的估算 (Cardinality) 卻只有 1 筆資料 :

由這邊可以發現優化器對於 Index 的估算錯誤,那是不是我們提供了錯誤的資訊給優化器了呢 ?
綜合兩點,我們將 Index IX_EMP1 進行 Rebuild ,然後重新蒐集統計資訊來修正統計錯誤 :

修正過後,優化器所選擇的 Plan 就變成了使用 Index 了 :

當我們對一段 SQL 的執行計畫有所疑問時,透過 10053 事件的分析就可以找到問題所在。