Oracle 版本: 19.19 , RAC
OS 版本: Linux 7.7
問題描述:
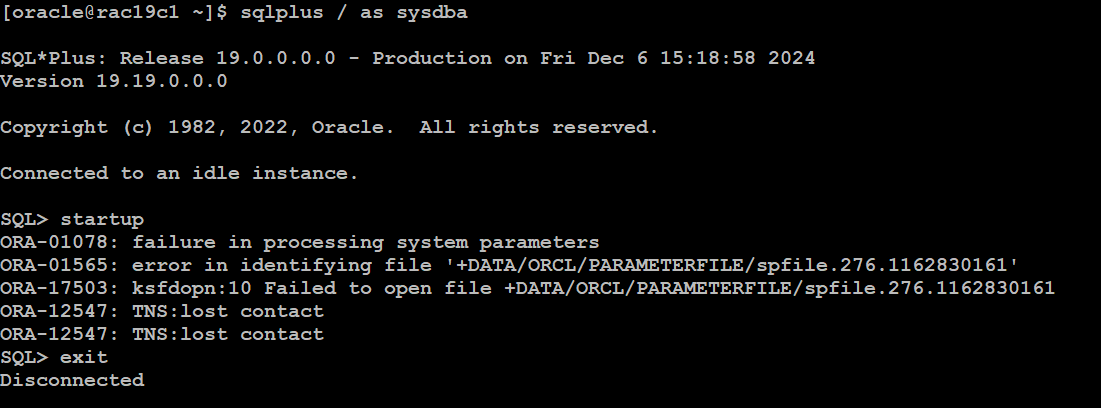
使用 srvctl 開啟資料庫時產生 ORA-01078 錯誤 :
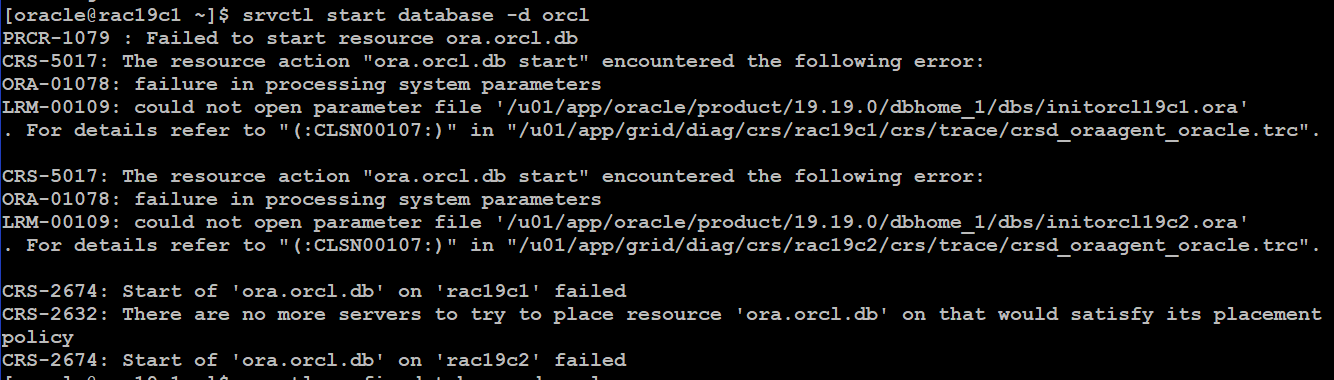
看起來是因為沒有參數檔造成啟動失敗,但是檢查設定的確參數檔是存在且設定沒有錯 :
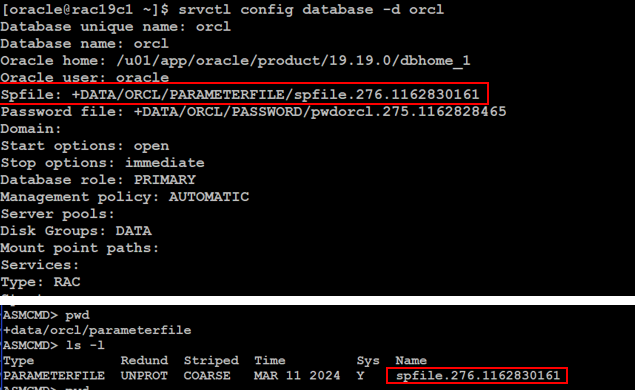
設定 initorcl19c1.ora 內容為 spfile= +DATA/ORCL/PARAMETERFILE/spfile.276.1162830161 ,嘗試使用 sqlplus 啟動資料庫,出現無法存取 spfile 的錯誤 :
問題分析:
存取 ASM 產生 TNS 錯誤有可能與 oracle 執行檔的權限錯誤有關,檢查 $ORACLE_HOME/bin 與 $GI_HOME/bin 底下 oracle 執行檔的權限,發現 $GI_HOME/bin/oracle 的權限錯誤 :
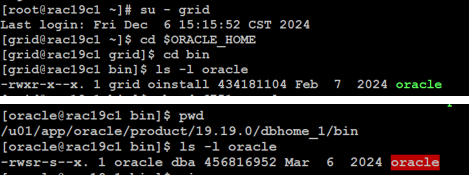
oracle 執行檔的權限必須為 6751 , $ORACLE_HOME/bin/oracle 的權限是對的,不過 $GI_HOME/bin/oracle 的權限是錯的。
解決方法:
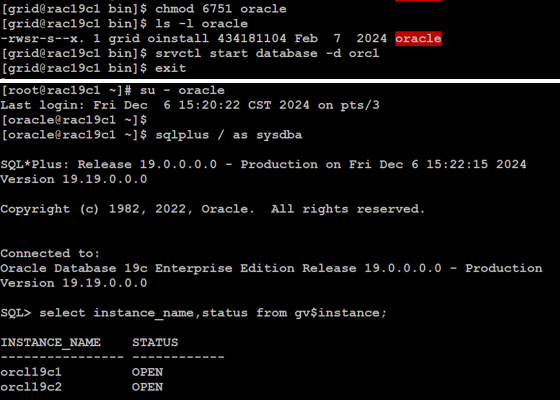
更正 $GI_HOME/bin/oracle 的權限為 6751 之後即可正常啟動資料庫 :
最後補充一下,如果使用不同使用者以及多個 group 安裝 GI 與 DB ,必須注意 $ORACLE_HOME/bin/oracle 與 asm disk 的 group 必須為 GI 設定的 Oracle ASM Administrator (OSASM) group ,這個設定在安裝後於 $GI_HOME/rdbms/lib/config.c (Linux 系統) 可以查詢的到 :
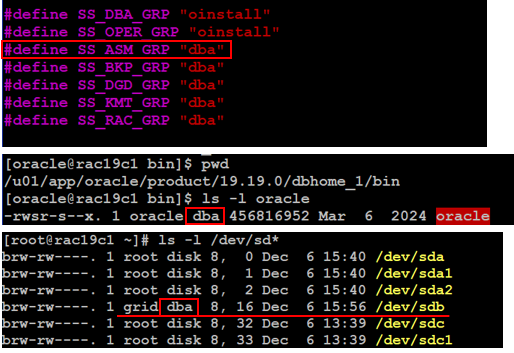
照標準安裝的話, OSASM 一般設定為 asmadmin ,不論是否使用 asmadmin,我們在安裝 GI 、 DB 的時候都必須要注意這個設定。