問題描述:
一句 SQL 語法的執行計畫不使用 Index 造成效能不佳 :
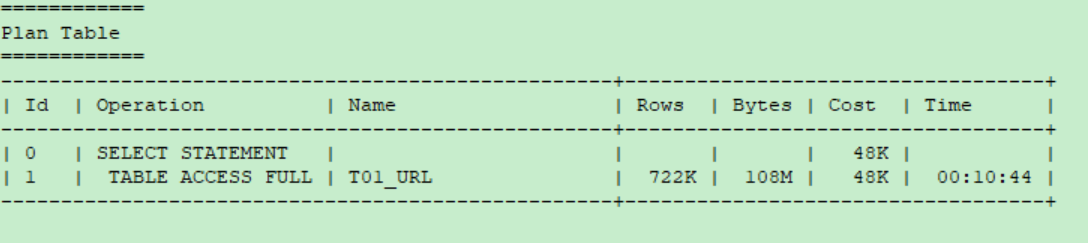
此 table 具有 Index IX1_T01_URL 但是 execution plan 卻沒有使用 :

問題分析:
收集 10053 trace 分析為何沒有使用 Index :
依據 10053 的內容來計算 cost ,公式如下 :
其中 :
CPU Cycles : 指執行一條指令所花費的時間, 單位為 納秒 1/1,000,000,000 秒
SRs = Single-block reads.
MRs = Multi-block reads.
sreadm = single block read time.
mreadtim = multi block read time.
LBs = Index Leaf Blocks.
IX_SEL = Index Selectivity.
IX_SEL_WF = Index Selectivity with Filters.
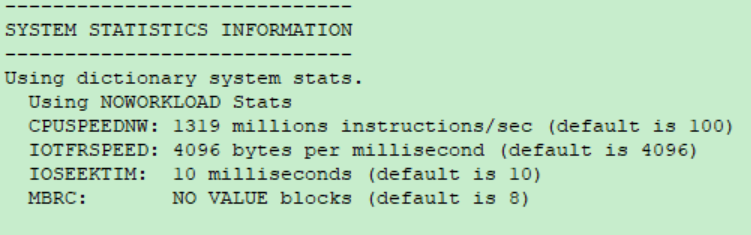
由 10053 所收集到的系統統計資訊可得到的數據如下 :
使用 Full Table Scan 的 Cost 約為 48657 :

套入公式計算如下 :
IO Cost = 48319
SREADTIM = IOSEEKTIM + (DB_BLOCK_SIZE / IOTFRSPEED) = 10 + (8192/4096) = 12
CPU Cost = CYCLES / (CPUSPEED * 1000 * SREADTIM) = 5351367865.712324 / (1319*1000*12) = 338.095013
Total Cost = IO Cost + CPU Cost = 48319 + 338.095013 = 48657.095
使用 Index Range Scan 的 Cost 約為 770733 :

其中 Index 所收集的統計資訊如下 :

套入公式計算如下 :
IO Cost = SRs + (MRs * (MREADTIM / SREADTIM)) = SRs = LEVELS + (LBs * IX_SEL) + (CLUF * IX_SEL_WF) = 3 + (47453 * 0.646377) + (8096445 * 0.091352) = 770301.971
CPU Cost = CYCLES / (CPUSPEED * 1000 * SREADTIM) = 6835653728 / (1319*1000*12) = 431.870971
Total Cost = IO Cost + CPU Cost = 770301.971 + 431.870971 = 770733.842
雖然手工計算出來的最終 cost 有一點誤差,但不影響我們分析。以結論來說,使用 Table Scan 的 cost 48657 小於使用 Index Range Scan 的 cost 770733 ,所以優化器最終使用的是 Table Scan。
進一步分析,針對 CPU Cost 來說, Table Scan 為 338 、 Index Range Scan 為 431 ,兩者其實差不多,但是 Index Range Scan 的 IO Cost 770733 卻遠遠大於 Table Scan 的 IO Cost 48319 ,這最終導致優化器認為使用 Index Range Scan 的成本太高而不選擇它。
由公式推斷,影響 Index Range Scan 的 IO Cost 最重要的因素為 IX_SEL 與 IX_SEL_WF ,也就是使用此 Index 的選擇性,這兩個因素的數值過大導致最終計算出來的 IO Cost 過大,所以從這邊可以知道,此 Index IX1_T01_URL(URL,TYPE) 的選擇性不佳,在這兩個欄位建立 Index 對於優化器來說是不適合的,必須尋求是否有更適合的欄位或是調整欄位的順序來建立 Index 。
結論:
Oracle CBO 會選擇 Cost 最低的路徑來做為最後執行的 Execution Plan ,由上述 10053 分析結果得知 IX1_T01_URL(URL,TYPE) 的選擇性不佳,但是由 SQL 語句來看,就只有 URL 、 TYPE 兩個 where 條件,理論上建立這個 Index 是合適的,那麼這邊就與優化器的判斷產生了矛盾。
以這個例子來說,使用 Index 應該是較好的選擇,但優化器因為數據公式化的關係無法做此判斷,所以本次我們應該使用 Hint ,或是建立 SQL Profile 來輔助優化器來使用 Index 。
