Materialized View 與 View 最大的不同是, View 本身只是存放一段 SQL 語法,針對 View 做查詢時,實際上是執行 View 本身的 SQL 語法;而 Materialized View 不僅僅是有一段 SQL 語法,更重要的是它直接把這段 SQL 語法所產生的結果直接存放起來,由於 Materialized View 是有存放資料的,因此它會占掉 Tablespace 的空間,就結構來說, Materialized View 就有如 Table 一樣,只不過它的資料來源是由一串 SQL 語句所產生,例如一個 Materialized View 的資料來源是 emp 與 departments 兩個 Table:
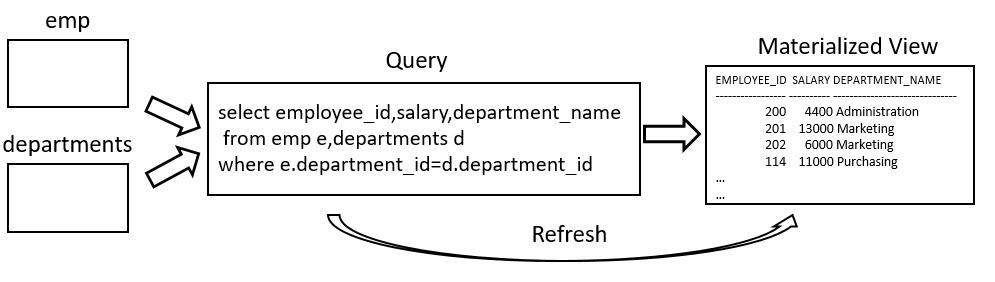
透過 SQL 語法將查詢 emp 、 departments 兩個 Table 的結果存放在 Materialized View 當中,由於 emp 與 departments 的資料可能會隨著時間有所異動,因此 Materialized View 會有一個 Refresh 的動作來更新這些異動之後的結果。
Materialized View 早期在 Oracle 8i 之前稱作 Snapshot ,其實這個名稱應該是比較合適,因為它是把一串的查詢結果儲存下來,然後定期的去更新這個結果,這個行為就有如資料的 Snapshot 一般,到了 Oracle 9i 才改稱為 Materialized View 。 Materialized View 資料更新 (Refresh) 的方式可分為增量同步 (Fast) 與全量同步 (Complete) ,增量同步是只有更新差異性的資料,這個方式需要建立 Materialized View Log 來記錄差異性的資料,而全量同步則不需要 Materialized View Log 。 Materialized View 的同步時間可以分為 On Demand 與 On Commit 兩種, On Demand 表示 Materialized View 只有在需要更新的時候才進行更新,可以是手動執行 DBMS_MVIEW.REFRESH 來進行更新,或是設定排程來定期更新;而 On Commit 表示在有資料異動且已經 Commit 之後立即進行更新,這種方式很明顯的是一種增量差異性的更新,所以 On Commit 條件下必須是要建立 Materialized View Log 。
建立 Materialized View 使用 create materialized view 語法,例如建立一個 On Demand 的 Materialized View:
SQL> create materialized view mv_emp as select employee_id,salary,department_name from emp e,departments d where e.department_id=d.department_id; |
建立 Materialized View 不加任何選項,預設就是 On Demand 模式,不會自動 Refresh ,必須執行 DBMS_MVIEW.REFRESH 來更新資料:
SQL> BEGIN DBMS_MVIEW.REFRESH( 'MV_EMP',method => '?', atomic_refresh => false); END; / |
其中 method 為執行 Refresh 的方式,可設定為:
f : 表示進行 fast refresh (增量同步) ,必須要有 Materialized View Log 。
c : 表示進行 complete refresh (全量同步) 。
? : 表示進行 force refresh ,由系統自行判斷要使用 fast 或是 complete refresh ,一般來說會以 fast refresh 為優先,無法進行 fast refresh 時 (例如沒有 Materialized View Log) ,就會執行 complete refresh 。
atomic_refresh 是用來設定 complete refresh 時的更新方式,預設為 TRUE ,表示進行 complete refresh 時會先將目前所有的資料 delete 然後再 insert 新的資料;設定為 FALSE 表示會使用 truncate 清除現有的資料然後再 insert 新的資料,在資料量很大的時候建議將此選項設定為 FALSE 來避免因為 delete 而產生過多的 archive log 。
另外也可以建立定時做 Refresh 的 Materialized View ,例如建立一天 Refresh 一次的 Materialize View :
SQL> create materialized view mv_emp refresh force start with sysdate next (sysdate + 1) with primary key as select employee_id,salary,department_name from emp e,departments d where e.department_id=d.department_id; |
其中 refresh 用來設定 refresh 的方式,預設為 force ,可以設定為 complete 或是 fast ; start with 是用來設定 refresh 的時間,設定之後會自動於排程新增一個 job 來執行 refresh 的動作 ; with primary key 表示增量同步時以 primary key 為基準來更新差異的資料, primary key 為預設選項,如果沒有 primary key 或無法使用 primary key 的情況之下,可以使用 with rowid ,以 rowid 的方式來進行差異資料的更新。
如果要建立 On Commit 或是能夠 fast refresh 的 Materialized View ,必須要先為 Based Table 建立 Materialized View Log ,例如 emp 沒有建立 primary key 所以使用 with rowid 選項, departments 有 primary key 則使用預設的 with primary key :
SQL> create materialized view log on emp with rowid; SQL> create materialized view log on departments with primary key; |
建立好 Materialized View Log 之後就可以建立一個 On Commit Refresh 的 Materialized View 了 :
SQL> create materialized view mv_emp refresh force on commit with primary key as select employee_id,salary,department_name from emp e,departments d where e.department_id=d.department_id; |
如果有多個 Materialized View 需要排程定期的來 Refresh ,可以使用 DBMS_REFRESH.MAKE 建立一個 Refresh Group 來定期的 Refresh 這個 Group 底下的所有 Materialized View ,例如建立一個一天 Refresh 一次的 Refresh Group ,其中包含了兩個 Materialized View 在這個 Group 裡面:
SQL> begin dbms_refresh.make(name=>'mv_group1',list=>'mv_emp1,mv_emp2', next_date=>sysdate,interval=>'sysdate + 1'); end; / |
其中 name 表示設定 Refresh Group 的名稱; list 表示要納入此 Group 的 Materialized View ; next_date 表示開始執行 Refresh Group 的時間; interval 表示間隔多久執行一次 Refresh ,這邊 sysdate + 1 表示一天執行一次,如果是一個小時執行一次,則可以設定為 sysdate + 1/24 。
Refresh Group 除了定時自動執行外,也可以使用 DBMS_REFRESH.REFRESH 手動進行 Refresh ,執行 DBMS_REFRESH.REFRESH 會 Refresh 這個 Group 底下所有的 Materialized View :
SQL> begin dbms_refresh.refresh('mv_group1'); end; / |
如果要將一個 Materialized View 添加到這個 Group ,則使用 DBMS_REFRESH.ADD ,例如增加 mv_emp3 到 mv_group1 :
SQL> begin dbms_refresh.add(name=>'mv_group1',list=>'mv_emp3'); end; / |
如果要將 Materialized View 移出 Group ,則使用 DBMS_REFRESH.SUBTRACT ,例如將 mv_emp1 移出 mv_group1 :
SQL> begin dbms_refresh.subtract(name=>'mv_group1',list=>'mv_emp1'); end; / |
如果要刪除 Refresh Group ,則使用 DBMS_REFRESH.DESTORY ,刪除 Refresh Group 同時會一起將這個 Group 底下所有的 Materialized View 移出這個 Refresh Group:
SQL> begin dbms_refresh.destroy('mv_group1'); end; / |
要得知 Refresh Group 的相關資訊,可以從 dba_refresh 、 dba_refresh_children 或是 user_refresh 、 user_refresh_children 來查詢:

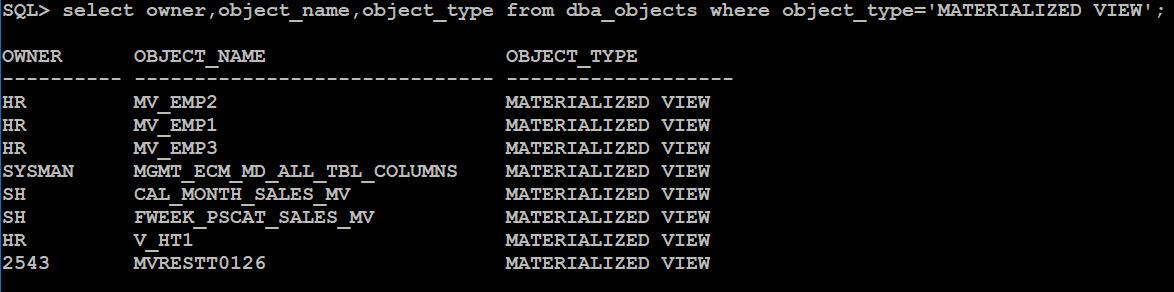
如果要得知 Materialized View 的相關資訊,可以從 dba_mviews 、 user_mviews ,或者是查詢 dba_objects 的 object_type='MATERIALIZED VIEW' :
Materialized View 是將一段查詢的結果存放起來,預設這些數據是不能異動的,如果有特殊需求,可以創建 Writeable Materialized View ,但限制上必須要可以執行 fast refresh 並且不能使用複雜的語法如 join 、 subquery 、 union 、 connect by 、 order by 、 group by…等 ,在建立時加上 for update 就可以建立 Writeable Materialized View :
SQL> create materialized view log on departments with primary key; SQL> create materialized view w_mv_dep for update as select department_id,department_name from departments; |
由於 Writeable Materialized View 必須要可以執行 fast refresh ,所以一定要先創建 Materialized View Log ,這邊要注意的是,如果 Materialized View Log 使用的是 with rowid ,那麼 Writeable Materialized View 也要必須使用 refresh fast with rowid 才可以建立,否則就會出現 ORA-12013: updatable materialized views must be simple enough to do fast refresh 的錯誤。
Materialized View 實務上最常運用的就是做資料的同步,例如建立一個 Materialized View 透過 DB Link 將員工資料由 HR 資料庫定期同步過來:
SQL> create materialized view mv_hr_emp refresh force start with sysdate next (sysdate + 1) with primary key as select * from employees@HR; |
另一個運用就是可以透過內部 Query Rewrite 機制來提升 SQL 的效能,由於 Materialized View 是事先將結果儲存起來,對於一些複雜的 SQL ,其執行計畫可以藉由存取 Materialized View 來快速的得到查詢的結果,例如一個 SQL 用來查詢每個部門的薪資總額 ( sum(salary) ) ,其執行計畫是對 emp 做 full table scan:

如果我們事先將 sum(salary) 這個部分建立 Materialized View ,那麼同樣查詢的執行計畫就會導向使用 Materialized View 來存取,這時在建立 Materialized View 的時候必須加上 enable query rewrite 才會被執行計畫所套用:

由於 Materialized View 已經將結果存放起來,所以走這個經由 Materialized View 的執行計畫,效能上會比原本直接存取 emp 再進行 sum(salary) 來的好,不過這個方法需要注意的是, Materialized View 的資料可能與原始 Table 不同步,這樣有可能造成查詢出來的資料是錯誤有差異的,如果要使用 Query Rewrite 的功能,最好是使用 On Commit 的 Materialized View ,避免因為資料的差異導致查詢結果有誤差。








