Oracle SQL Loader 是一個能夠把資料從檔案匯入到資料庫的一種工具,檔案格式可以是純文字檔 (Text File) ,或者是以逗號分隔 (CSV 格式) 的檔案…等,只要是檔案中的資料欄位可以與資料庫 Table 的欄位互相匹配,基本上都可以使用 SQL Loader 將資料從檔案匯入到 Oracle 資料庫。
執行 SQL Loader 使用的是 sqlldr 這個命令,只要執行 sqlldr 就會提示如何使用:

實際上只要簡單執行 sqlldr <帳號>/<密碼>@<db> sqldr.ctl 就可以了,意思是使用 sqlldr 登入資料庫並執行 sqldr.ctl 裡面的內容, sqldr.ctl 是 SQL Loader 的 control file ,其實就是所謂的設定檔,裡面要定義資料來源、欄位的 mapping …等資訊,這個檔案是我們執行 sqlldr 之前要自己編寫的,整個 SQL Loader 的核心其實就在於如何撰寫這個 control file 。
SQL Loader 使用的 control file 是有固定格式的,必須遵循這四個項目依序來編寫:
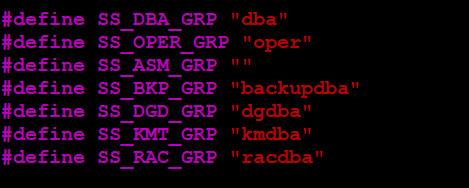
Options 子句: 設定 SQL Loader 的 Options ,例如容錯筆數、是否使用 Direct Load 、 是否使用 Parallel …等, Options 子句可以添加或者是不使用。
Load Data 子句: 設定資料來源。
Load Method 子句: 設定匯入資料的方式:
INSERT : 直接使用 insert 命令匯入資料,這個方式必須在 Table 沒有任何資料的時候才可以使用。
APPEND : 使用 insert 匯入資料,且資料都是 new rows ,在原本的資料之後新增到 Table 中。
REPLACE : 使用 delete 的方式刪除 Table 所有的資料,然後再 insert 資料進去。
TRUNCATE : 使用 truncate 的方式清除 Table 所有的資料,然後再 insert 資料進去。
Into Table 子句 : 用來設定資料來源與資料庫 Table 欄位的 mapping 。
了解了 control file 的格式之後,就可以來編寫它,例如要將一個 CSV 格式的資料匯入 emp 這個 Table 當中,那麼就可以編輯一個名為 emp.ctl 的 control file 如下 :
首先 options 設定容錯筆數為 100 ,並且執行 direct load ; Load Data 子句設定來源檔案為 emp.csv ; Load Method 子句設定為 TRUNCATE ; into table emp 表示將資料匯入 emp 這個 Table ,以下將針對欄位做 mapping :
fields terminated by ',' : 表示資料來源的欄位是以逗號分隔。
optionally enclosed by '"' : 表示資料來源當中,使用雙引號 “ 框起來的資料視為同一個欄位的資料,例如一筆資料為 “ Taipei,Taiwan “ ,雖然是逗號分隔,但是在雙引號裡面, “ Taipei,Taiwan “ 代表是同一個欄位的資料,如果沒有用雙引號,那麼在逗號分隔下,就會區分為兩個欄位 Taipei 與 Taiwan 。
trailing nullcols : 代表這個欄位如果沒資料的話,那麼就視為是 null 。
最後將 Table 所有的欄位列出來,每個逗號分隔的資料剛好可以跟 Table 的這些欄位做匹配,這邊要注意的是, SQL Loader 讀取資料的時候,預設的資料型態都是 char ,如果 Table 所定義的欄位型態不是 char 的話,那麼就要在這邊進行設定,例如 HIRE_DATE 這個欄位的型態為 DATE ,所以在這邊就要特別註記為 DATE ,且格式為 "YYYY-MM-DD hh24:mi:ss" 。
編寫好 control file 之後,那麼就可以使用 sqlldr 將資料匯入資料庫了:

其中 bad 是設定 bad file ,表示如果有資料格式錯誤無法匯入,那麼就將這筆資料寫入 bad file 裡面; discard 表示 discard file ,雖然資料格式正確,但是條件不符,那麼就把這筆資料寫入 discard file ,例如匯入的資料當中與 Primary Key 的欄位出現重複的資料,那麼這些重複的資料就無法匯入,並且寫入 discard file 當中。
sqlldr 執行完畢後,可以檢視 log file 確認是否匯入的過程當中有產生錯誤,以及匯入的資料量是否正確:

除此之外,如果資料是屬於固定長度格式的 Text File ,也可以設定 control file 如下:
不同於逗號分隔,無須設定 “fields terminated by” 等參數,而改由 POSITION 參數設定,直接做欄位的 mapping , SALE_NO POSITION(1:5) 表示 Text File 的第一位到第五位的資料屬於欄位 SALE_NO ; SNAME POSITION(6:13) 表示第六位到第十三位的資料屬於欄位 SNAME … 以此類推。
SQL Loader 的 control file 所可以註記的資料型態共三種 :
CHAR : 代表文字型態,為預設的資料型態,預設的長度為 255 , Table 定義的 char 或 varchar2 ,對 SQL Loader 來說都是以 char 表示。如果 Table 的資料長度大於 255 (例如 1000) ,那麼就要特別註記長度為 char(1000) 。
INTEGER EXTERNAL (或 DECIMAL EXTERNAL) : 代表數字型態, Table 定義的數字型態如 Number 、 INT …等,對 SQL Loader 來說都是以 INTEGER EXTERNAL (或 DECIMAL EXTERNAL) 來表示。
DATE : 代表日期型態,與 Table 所表示的 DATE 意義相同。
實務上最常用的大概就是匯入固定長度的 Text File 與 CSV 格式的檔案了,雖然 SQL Loader 的 control file 不是那麼好編寫,但只要熟悉之後,這會是一個很好用的工具。