Oracle Data Pump 為 Oracle 10g 開始推出的新功能, Data Pump 可以說是加強版的 Export 、 Import ,由 expdp 與 impdp 命令取代了原本的 exp 與 imp ,與傳統的 exp 、 imp 不同的是, exp 與 imp 是使用外部指令連接到資料庫進行匯出與匯入的動作,而 expdp 與 impdp 則是把外部指令轉換為資料庫內部的命令,使用的是 dbms_datapump 來進行匯出與匯入的動作,也就是說 expdp 與 impdp 是在資料庫內部運行的,當執行了 expdp 或 impdp ,會在資料庫產生一個 Data Pump Job ,經由這個 Job 來呼叫 dbms_datapump 從而完成匯出與匯入的動作,由於 Data Pump 是在資料庫內部運行的,並不會因為執行 expdp 、 impdp 的視窗被關閉後就會中斷,而 exp 與 imp 則是運行視窗被關閉後就會被中斷;另一個不同是,由於 Data Pump 是在資料庫內部運行,所以匯出的 Dump 檔案必須存放在資料庫主機上,而傳統的 exp 則是可以透過 tnsnames 將 Dump 檔匯出到 Client 主機上。
由於 Data Pump 所匯出的 Dump 檔案必須存放在資料庫主機上,所以在執行 Data Pump 之前必須於資料庫建立一個 Directory , Directory 的用意是在資料庫建立一個名稱,這個名稱是要對應作業系統上的一個位置,之後資料庫就會知道要將 Dump 檔匯出到作業系統上的那一個位置, Directory 必須使用 sys 使用者建立,而 sys 也是 Directory 的擁有者,如果其他使用者也要使用的話,必須授權給它,例如於資料庫建立兩個 Directory , expdir 與 impdir ,然後授權給 scott 與 hr 這兩個使用者:
如果不使用某個 Directory ,可以使用 drop directory 命令來刪除。
透過 dba_directories 可以查詢目前資料庫所建立的 Directory 與所對應的路徑:

Data Pump Export 使用的是 expdp 命令,執行 expdp help=y 會列出所有可以使用的參數,一般來說只要簡單的指定帳號密碼 、 Dump 檔案存放路徑 (Directory) 、 Dump 檔案的名稱以及所要匯出的資料範圍 (Full 、 Schemas 、 Tables) 就可以進行匯出的動作:
Data Pump 會於資料庫內部建立一個 Job 來處理,透過 dba_datapump_jobs 可以查詢目前所進行的作業:

在執行 expdp 的時候可以帶入參數 job_name 自行為這個 job 命名,如果沒有使用 job_name 的話,系統會自行為這個 job 進行命名。
由於 Data Pump 是在資料庫裡面建立 Job 來執行,所以當 expdp 的執行介面被關閉時, Data Pump 的作業並不會因此停止,重新登入後可以使用 attach=<job_name> 來重新回到 Data Pump 執行的狀態,例如重回 expfull 這個 Job 的執行狀態:
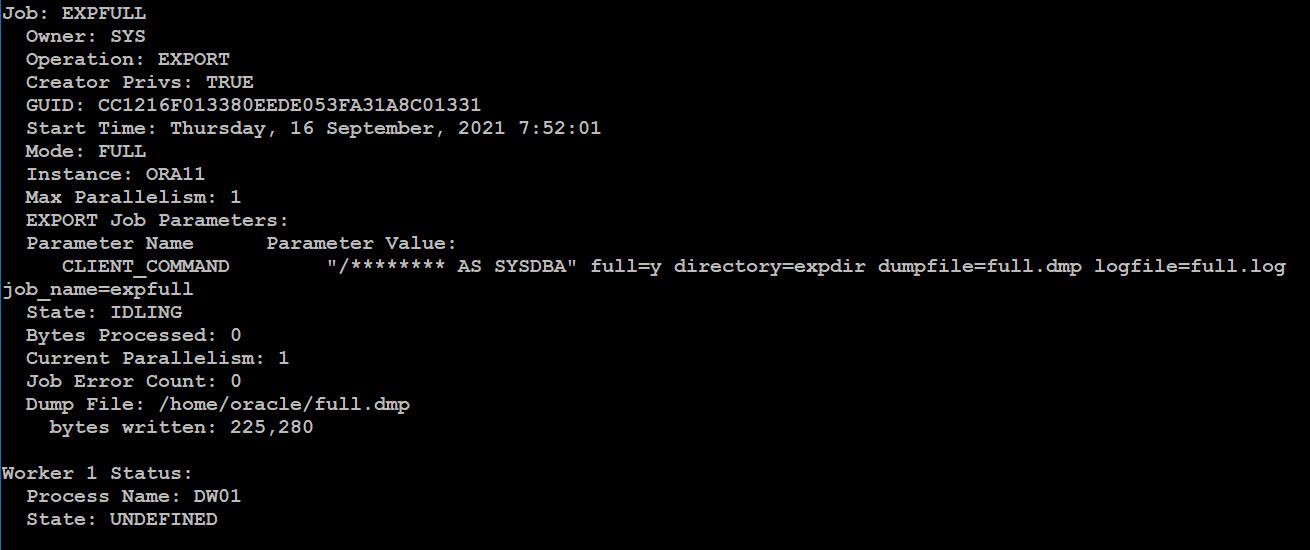
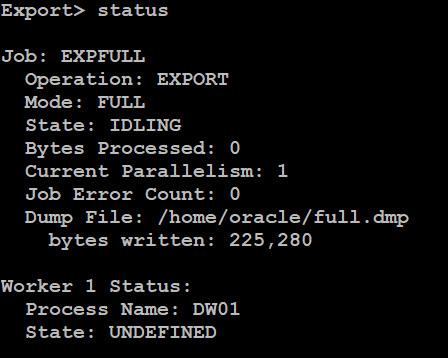
在 attach 回去之後會進入到 Export> 介面,在此介面下可以對此 Job 進行狀態查詢 (status) 、 暫時停止 Job (stop_job) 、 重新開始 Job (start_job) 、 終止 Job (kill_job) 等動作:
expdp 一些比較常用的選項例如在 dumpfile 可以使用 %U ,這個選項可以自動切分並命名多個 Dump 檔案,例如 dumpfile=exp%U.dmp 就會自動產生 exp01.dmp 、 exp02.dmp 、exp03.dmp 等編號的 Dump 檔; parallel 可以設定多個 threads 來進行 Export 的動作; content 可以設定只匯出結構 (content=metadata_only) 或者是只匯出資料 (content=data_only) ; exclude 與 include ,可以指定只匯出或者是排除某些物件,例如只匯出 Procedure (include=procedure) 、不匯出 Index (exclude=index) ; parfile 用來指定參數檔, expdp 可以將所有要使用的參數設定為一個參數檔,然後用 parfile 來指定它就可以。
expdp 同樣也可以使用 query 條件式來匯出某些部分的資料,例如只匯出 employee_id < 200 的資料:
Data Pump Import 使用的是 impdp 命令,執行 impdp help=y 會顯示出所有可以使用的參數,同樣的只要簡單輸入帳號密碼, Dump 檔案名稱與位置就可以進行匯入的動作了。 impdp 與傳統的 imp 最大的不同是,傳統的 imp 要匯入 Table 的時候,必須先把相對應的使用者先建立好才可以進行匯入的動作,而 impdp 如果來源的 Dump 檔案是以 schema 層級匯出的話,如果使用者不存在,那麼 impdp 就會在匯入 Table 前自動建立使用者。 impdp 較常使用的參數除了上述 expdp 所提過的 parallel 、 exclude 、 include 、 job_name 、 parfile 之外,當匯入的 Table 已經存在的時候必須使用 table_exists_action 來告訴 impdp 必須進行何種動作, table_exists_action 可以為 append (接續著目前存在的資料進行匯入) 、 truncate (將 Table 的所有資料清空後重新匯入) 、 replace (將 Table 重新建立後再進行資料的匯入) 、 skip (跳過此 Table) ; remap_schema 用來將物件匯入到不同於來源的使用者; network_link 透過 db link 直接匯入資料,使用這個選項可以在不產生 Dump 檔案的情況下直接從來源資料庫將資料匯入。例如:
使用 Data Pump 必須要注意的是,如果要終止掉正在執行的 Export 、 Import 作業,傳統的 exp 與 imp 只需要從作業系統執行 kill -9 指令就可以終止,但是 expdp 與 impdp 是在資料庫內部產生 Job 來執行,光是 kill 掉 expdp 、 impdp 是無法終止 Data Pump 的,這麼做反而會讓 Data Pump Job 殘留在資料庫裡面,正確的作法必須要使用 attach=<job_name> 進入到 Export> 或是 Import> 介面,然後執行 kill_job ,這樣才是完整的終止 Data Pump 作業。
Data Pump 不像傳統的 exp 、 imp 必須再特別設定環境變數 NLS_LANG ,因為 Data Pump 是在資料庫內部運行,所以不會有字元集不匹配的問題。由上述範例可以看到, Data Pump 可以使用的選項非常多,使用起來比起傳統的 exp 、 imp 更有彈性也更為便利,雖然現今版本的資料庫還保有 exp 與 imp 的命令,但是已經漸漸地很少使用它了,而是使用 expdp 與 impdp 進行取代。
沒有留言:
張貼留言