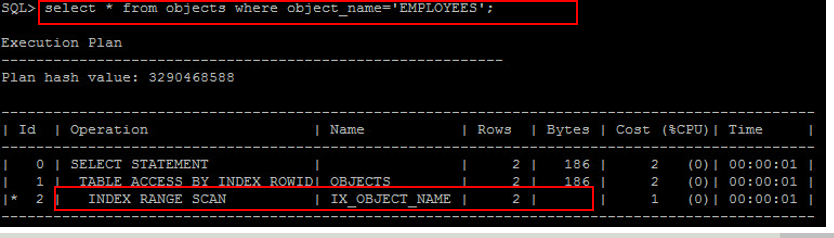
Index 的建立必須要以資料的選擇性 (Selectivity) 為原則來建立,我們使用 Index 的目的,就是要能夠快速地過濾出資料, Index 是否有效率取決於它是否能夠過濾出最少的資料,其中最佳實踐就是 Primary Key 與 Unique Index ,因為這兩者都保證資料必須是唯一值,透過這兩者所過濾出來的資料筆數一定是 1 筆,這也是能過濾出來的最小值,因此 PK 與 Unique Index 是最有效率的 Index ,其餘的 Non-Unique Index 就必須要考慮到選擇性 (Selectivity) 的問題。
選擇性 (Selectivity) 是指所查詢的資料量占所有資料的比例,若我們檢索的資料幾乎接近全部的資料量,那使用全表掃描會比使用 Index 來的適合,若是檢索的資料量只占整體的一小部份,那麼使用 Index 來快速過濾資料就相對比較適合;我們以ㄧ個例子來做說明,首先列出 employees 這個 Table 當中每個department_id 於有多少筆資料 :

若我們檢索 department_id = 50 ,總共有 45 筆資料,占全部資料約 42% ,這時有可能會選擇以 Full Table Scan 來做查詢 :

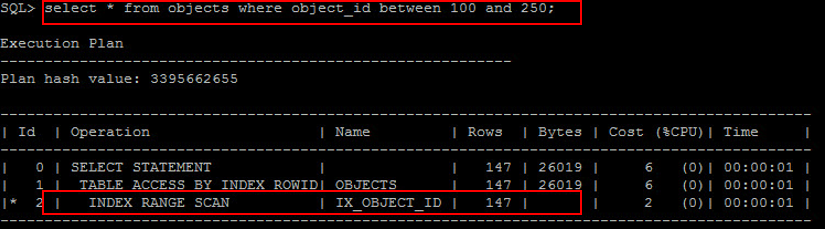
若檢索 department_id = 100 ,只有 6 筆資料,占全部資料僅 5% ,此時就會以 Index 來做查詢 :

由上述的例子可知,若資料的選擇性不好 (Bad Selectivity,意即檢索的資料占絕大多數比例) ,即使有 Index 也不一定會使用它。一般來說,當檢索的資料占所有資料的比例小於 15% 的時候,比較適合建立 Index 。
在了解資料選擇性的概念之後,就可以開始對一段 SQL 來建立 Index , SQL Statement 中 where 條件的欄位,就是我們用來建立 Index 的目標,因為where 條件與資料的選擇性息息相關,假設一段查詢如下:
SQL> select * from employees where employee_id = 100 and department_id = 50; |
這時 employee_id 與 department_id 這兩個欄位都是建立 Index 所考慮到的目標,由資料的選擇性來看,一個員工只會有一個員工 id 且不會重覆,所以 employee_id = 100 只會有一筆資料,比起 department_id = 50 有 45 筆資料來得適合,因此以這個查詢來說,我們應該對 employee_id 這個欄位建立 Index 。
如果將 employee_id 與 department_id 建立一個複合索引 (Composite Index) ,是否效能會更好 ? 以這個例子來說,建立單欄位索引的選擇性與建立複合索引的選擇性是相同 (employee_id = 100 與 employee_id = 100 and department_id = 50 兩個條件都只會檢索到一筆資料) ,而複合索引所需要的儲存空間與 I/O 也較多,因此複合索引在此是不適合的。
是否需要建立複合索引 (Composite Index) 也是以資料的選擇性為原則來做考量,例如一段查詢如下 :
SQL> select * from employees where first_name = 'William' and last_name = 'Smith'; |
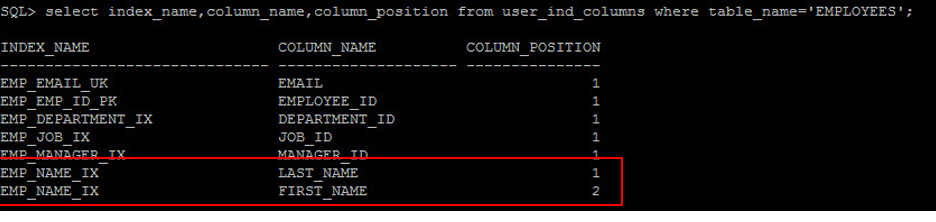
此時須考量到 employees 可能有多個員工的 first_name 為 William ,同樣也有可能有多個 last_name 為 Smith ,但只會有一位員工叫做 'Smith William' ,就算是同名同姓,這樣子的筆數也是相對少,因此對這個查詢來說,建立一個含有 (last_name , first_name) 的 Composite Index 選擇性較高,比建立單個欄位的Index來得適合。不過對於複合索引來說,還需要考慮到欄位的順序,最常被使用的欄位應該放在複合索引的最前面,因為優化器會依複合索引中欄位的順序來比對 where 條件是否有符合的欄位可做檢索,若複合索引的第一個欄位不存在 where 條件中,即使 where 條件含有複合索引中第二或第三個欄位,優化器也不會選擇使用複合索引,或是使用較差的 Index Skip Scan 來做查詢。
若 SQL 語句有 join 的情況下,同樣的需考慮哪個 Table 的選擇性較好,例如 :
SQL> select last_name||' '||first_name,department_name from employees a,departments b where a.department_id=b.department_id; |
此時共有兩個欄位 a.department_id 與 b.department_id 可供選擇來作為Index ,以這個例子來說,同樣是名叫 department_id 的欄位,對於存放部門資訊的 departments 這個 Table 來說, 部門名稱是不會重複的,所以它的 department_id 是唯一值;而存放員工資訊的 employees 這個 Table , department_id 是用來紀錄每個員工的所在部門,不同的 employees_id 可能會對應到相同的 department_id ,綜合來說,使用 departments 的 department_id 會比 employees 的 department_id 能夠過濾出來較少的資料,所以將 Index 建立在 departments 的 department_id 上比較適合。
另一種可以建立複合索引的情況,就是將查詢的欄位也包括在 Index 裡面,這個做法是為了減少回表所消耗的時間,例如 :
SQL> select object_name from objects where object_id = 100; |
以這個查詢來說,建立複合索引 (object_id , object_name) 會比只建立單一欄位 (object_id) 的索引來得適合,因為複合索引(object_id , object_name) 已經把將要查詢的字段 object_name 包含進去,無需再由ROWID 回去反查 Table 中 object_name 的欄位。
既然資料的選擇性 (Selectivity) 這麼重要,那麼實務上要如何判斷欄位的選擇性好不好 ? 透過 dba_tab_columns 當中的 num_distinct 欄位可以快速的判斷哪一個欄位的選擇性較好, num_distinct 代表這個欄位的 distinct value ,數值越大代表數據的種類越多,如果 num_distinct 的數值等於整個 Table 的全部筆數,那麼表示這個欄位的資料都是唯一值,所以它的 distinct value 等於總筆數,換句話說,只要是 num_distinct 越大,代表這個 where 條件越能夠過濾出越少資料,也就越適合建立 Index ,使用 num_distinct 的概念,我們再來判斷上述這句查詢的哪個欄位適合建立 Index :
SQL> select last_name||' '||first_name,department_name from employees a,departments b where a.department_id=b.department_id; |
查詢 dba_tab_columns 得到這兩個 Table 欄位的 distinct value :

employees - department_id 的 distinct value 為 11
departments – department_id 的 distinct value 為 27
所以 departments 的 department_id 比較適合用來建立 Index 。
只要掌握了選擇性 (Selectivity) 的概念與 distinct value 的用法,就可以建立有效率的 Index ,避免無端、過多 Index 的情況。