Index 的掃描資料方式可分為 Index Unique Scan 、 Index Range Scan與 Index Fast Full Scan ,其中 Index Fast Full Scan 是以 multi block 進行掃描,其餘是以 single block 一次只讀取一個 Block 進行掃描。針對這三種掃描方式,我們建立一個測試 table 來做說明 :
於 object_id 欄位建立一個 Unique Index :
於 object_name 欄位建立一個 Non-Unique Index :
當我們對具有 Unique Index 的欄位進行 "=" 條件檢索時,此時會以 Index Unique Scan 進行掃描 :

對具有 Non-Unique Index 的欄位進行 "=" 條件檢索時,則是以 Index Range Scan 進行掃描 :
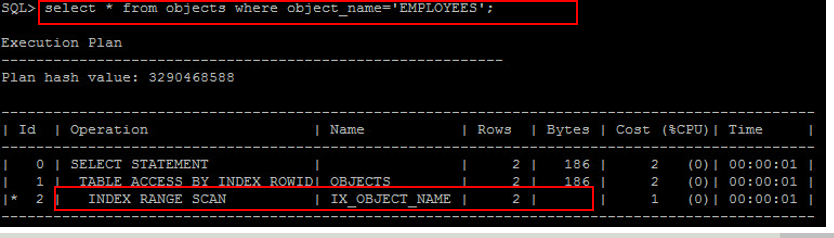
當進行範圍檢索時,不論此欄位具有 Unique Index 或是 Non-Unique Index 時,都會使用 Index Range Scan :
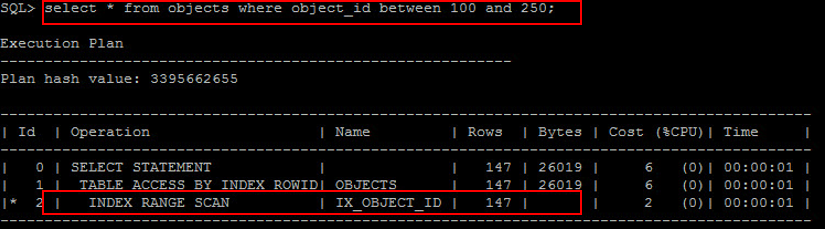
若是所要查詢的列都包含在 Index 裡面的話,便可直接從 Index 返回資料,無需再由 ROWID 回去反查 Table 的列,這種情況就會發生 Index Fast Full Scan ,但前提是此欄位必須為 Not Null ,否則會變成 Full Table Scan 。例如只針對 object_id 這個具有 Index 的欄位做 select ,當 object_id 存在 Null 值時會發生 Full Table Scan :


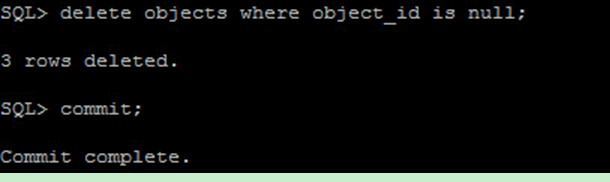
刪除 Null 的資料並將欄位屬性設定為 Not Null 之後,同樣的查詢就會變成 Index Fast Full Scan :


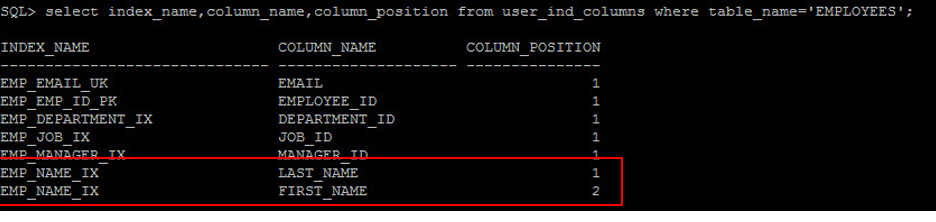
在 Oracle 10.2.0.5 版本開始,多了一個 Index Skip Scan 的功能,以往複合欄位的 Index 必須 where 條件有使用到第一個欄位才會用到此 Index ,而 Index Skip Scan 則是當 where 條件沒使用到複合索引的第一個欄位時所使用的 Index 掃描方式,例如 employees 這個 Table 有複合索引 EMP_NAME_IX (LAST_NAME,FIRST_NAME) :
此時查詢的 where 條件沒使用到第一個欄位 (LAST_NAME) ,就會使用 Index Skip Scan 進行掃描 :

而 Index Skip Scan 的原理是 Recursive SQL 會將原本的查詢改寫為具有第一個欄位 (LAST_NAME) 的查詢,並將所有 LAST_NAME 的數值 Union 起來,透過 Recursive SQL ,原本的查詢就會變成 :
由於 Recursive SQL 使用了第一個欄位 (LAST_NAME) ,所以這個複合索引也就可以使用到了,但是這個方式的缺點也是顯而易見的,假設 LAST_NAME 的筆數很多的話, Recursive SQL 這樣子處理是相對沒有效率的,因此在大部分時候 Index Skip Scan 是很沒有效率的,表面上雖然是使用到 Index ,但這個掃描方式不見得會比較快。
使用 Index 最主要的目的就是能過快速的找到資料,因此能夠過濾出越少資料的掃描方式是最好的,首選當然就是 Index Unique Scan ,這也是為什麼建議 Table 上都要有 Primary Key ,因為 PK 是唯一值且 Not Null ,一定是使用 Index Unique Scan ,過濾出來的資料是最少所以是最有效率的,其次大多時候我們看到的都是 Index Range Scan ,此時 Index 掃描有沒有效率,就與資料的選擇性 (selectivity) 有關。
沒有留言:
張貼留言